R基础知识
包的安装,载入,查找,更新,卸除加载的包,删除包
| 功能 | 函数 |
|---|---|
| 安装 | install.packages(“包名”) |
| 查找 | library() 可以查找所有已经安装的包 |
| 载入 | library(“包名”) |
| 卸除加载的包(并未删除) | detach(“包名”) |
| 更新 | updata.packages(“包名”) |
| 删除 | remove.packages(“包名”) |
查看帮助信息
| 函数 | 用途 | 实例 |
|---|---|---|
| help.start() | 直接进入一个帮助文档的总页面 | help.start() |
| help(函数名)/?函数名 | 显示该函数的帮助页面,但是有时候寻找的只是已经载入的包中,可以加上 try.all.packages=TRUE 来让它搜索所有的包。同时对于某些特殊的函数必须使用双引号,比如if等。 |
help(mean)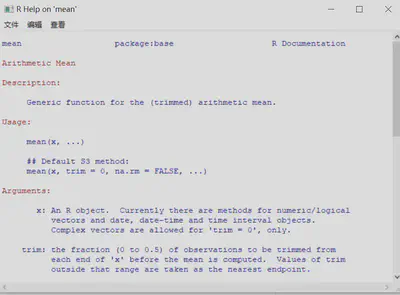 help(“bs”) No documentation for ‘bs’ in specified packages and libraries:you could try ‘??br’ help(“bs”,try.all.packages=TRUE) Help for topic ‘bs’ is not in any loaded package but can be found in the following packages: Package Library splines D:/R/R-3.6.3/library |
| apropos(“字符串”) | 搜索含有该字符串的函数的帮助文档,但是只是在已经安装的包中寻找 | apropos(“means”) |
| help.search(“字符串”) | 列出所有在帮助页面中含有该字符串的函数,不仅仅是名字 | help.search(“mean”)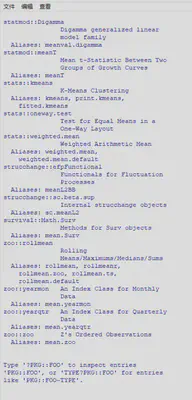 |
| find(“函数名”) | 找出含有该函数的程序包 | find(“mean”) r$> find(“mean”) [1] “package:Matrix” “package:base” |
变量,常量和赋值
r是基于对象的语言,变量名实际就是对象名。
变量名由点号,下划线,字母,数字组成,以字母或下划线开头,或者在这两个前面加个点号也行。
有了变量就可以赋值,可以用 =,-> ,<- 来赋值。
常量就是不变的值。
运算符与运算函数
运算符是特殊的函数,分为算数运算符,比较运算符,逻辑运算符,赋值符,和其他运算符。
算数运算符>比较运算符>逻辑运算符>赋值符
算数运算符中:指数>乘除>加减
比较运算符:无大小
逻辑运算符:!>&>| 非大于并大于或
常见运算符:
| 符号 | 含义 | 实例 |
|---|---|---|
| 算数运算符 | ||
| +,- | 加,减 | |
| *,/ | 乘,除 | 5/3 为浮点数 |
| %% | 求余 | |
| %/% | 求整 | 5%/%3 为 1 |
| ^ | 幂 | |
| 比较运算符 | ||
| >,<,>=,<=,==,!= | 大于,小于,大于等于,小于等于,等于,不等于 | |
| 逻辑运算符 | ||
| ! | 非,取逻辑值的反运算 | !TRUE |
| & | 并,比较的对象全为真才是真 | TRUE&FALSE [1] FALSE c(TRUE,TRUE)&c(TRUE,FALSE) [1] TRUE FALSE |
| && | 如果比较的是向量只比较第一组值。 | c(TRUE,TRUE)&&c(TRUE,FALSE) [1] TRUE c(FALSE,TRUE)&&c(TRUE,FALSE) [1] FALSE |
| | | 或 | |
| || | 如果比较的是向量只比较第一组值。 | |
| xor | 异或,两个逻辑值不一致时为真 | xor(TRUE,FALSE) [1] TRUE |
| 赋值符 | ||
| =,<- | 赋值 | |
| 其他运算符 | ||
| $ | 提取符 | |
| %*% | 矩阵相乘 | |
| all() | 一个向量中所有值全为真则为真 | |
| any() | 一个向量中有值为真则为真 |
常用运算函数:
x=c(1,2,3,4)
x2=c(5,6,7,8)
y=matrix(c(1,2,3,4,5,6,7,8),2,4)
y2=matrix(c(3,8,5,7,3,6,7,4,2),3,3)
z=c('a','c','b')| 函数 | 功能 | 实例 |
|---|---|---|
| sum(x) | 求和 | sum(x) 10 sum(y) 36 |
| range(x) | 查看数值的范围 | range(z) [1] “a” “c” range(x) [1] 1 4 range(y) [1] 1 8 |
| length(x) | 返回数据长度 | r$> length(x) [1] 4 length(y) [1] 8 |
| prod(x) | 序列中所有值相乘 | prod(x) [1] 24 prod(x,x2) [1] 40320 prod(y) [1] 40320 |
| mean(x) | 求所有值的平均值 | mean(x) [1] 2.5 mean(y) [1] 4.5 |
| max(x) | 求最大值 | max(z) [1] “c” |
| median(x) | 中位数 | median(z) [1] “b” |
| min(x) | 求最小值 | |
| cov(x,y) | 求协方差 | 矩阵每一列是一个变量 cov(y2) [,1] [,2] [,3] [1,] 6.333333 -5.166667 -3.166667 [2,] -5.166667 4.333333 1.833333 [3,] -3.166667 1.833333 6.333333 |
| cor(x,y) | 求两个变量之间相关系数 | |
| var(x) | 对矩阵求协方差,对向量求方差 | var(y2) [,1] [,2] [,3] [1,] 6.333333 -5.166667 -3.166667 [2,] -5.166667 4.333333 1.833333 [3,] -3.166667 1.833333 6.333333 var(y2[,1]) [1] 6.333333 |
| cor(x) | 求矩阵的相关系数 | cor(y2) [,1] [,2] [,3] [1,] 1.0000000 -0.9862414 -0.5000000 [2,] -0.9862414 1.0000000 0.3499566 [3,] -0.5000000 0.3499566 1.0000000 |
| which.max(x) | 返回第一个最大值的位置 | which.max(y2) [1] 2 which.max(c(1,2,2,1)) [1] 2 |
| which.min(x) | 返回第一个最小值的位置 | |
| round(x, n) | 转置 | |
| pmin(x,y,…) | 对所有向量或矩阵的值进行比较,长度不等可以循环,取较小的值组成一个与最长长度相同的向量 | pmin(x,x2) [1] 1 2 3 4 pmin(y,y2) [1] 1 2 3 4 3 6 7 4 1 |
| pmax(x,y,…) | 返回所有最大值 | |
| rev(x) | 倒序 | rev(x) [1] 4 3 2 1 rev(y2)[1] 2 4 7 6 3 7 5 8 3 |
| sort(x) | 排序 | sort(y2) [1] 2 3 3 4 5 6 7 7 8 |
| cumsum(x) | 累加 | cumsum(x) [1] 1 3 6 10 |
| rank(x,ties.method=?) | 对一维数组或向量进行排序,给每个值赋予一个排名,对相同值排名有五种规则(first:从小到大,相同值先出现的小,max:取最好水平,min:取最差水平,average:取平均水平,random:随机排名) | rank(c(6,9,10,3,9,5),ties.method=?) “first”:3 4 6 1 5 2 “max”:3 5 6 1 5 2 “min”:3 4 6 1 4 2 “average”:3.0 4.5 6.0 1.0 4.5 2.0 “random”:3 5 6 1 4 2 |
| cumprod(x) | 累乘 | cumprod(x) [1] 1 2 6 24 |
| log(x,base) | 求对数 | log(5,80) [1] 0.3672816 log(80,5)[1] 2.722706 |
| cummin(x) | 输出目前为止碰到的最小值,如果后面碰到了更小的,就变成更小的值,依次往下推 | cummin(y2) [1] 3 3 3 3 3 3 3 3 2 cummin(c(3,5,2,4,1,0)) [1] 3 3 2 2 1 0 |
| cummax(x) | 输出目前为止碰到的最大值,如果后面碰到了更大的,就变成更大的值,依次往下推 | |
| scale(x,center,scale) | 规范化处理,归1化。center为true时,减去均值,false不减;scale为true时除标准差,false不除。两个值默认都为true,所以x_i=(x_i-mean(x))/sd(x) |
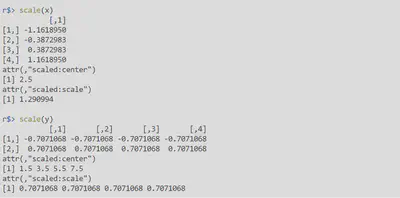 |
| unique(x) | 去除掉重复元素的向量数据框或数组 | unique(c(1,3,3,7,5,4)) [1] 1 3 7 5 4 unique(matrix(c(1,2,1,3,5,3),3,2)) [,1] [,2] [1,] 1 3 [2,] 2 5 矩阵去掉的是重复行 |
| match(x,y) | 返回x中元素在y中的位置,有的返回位置,没有的返回na | match(c(3,1),c(1,3)) [1] 2 1 match(c(4,3),c(4,1)) [1] 1 NA |
| sample(x,size) | 从向量或数据框等中随机抽取n个数 | sample(x,2) [1] 3 1 sample(y,2) [1] 4 3 sample(y,2) [1] 6 4 |
| which(x == a) | 返回所有等于a的值的位置 | which(y2==3) [1] 1 5 which(x==2) [1] 2 |
文件读写
设定路径
利用getwd函数获取当前路径 利用setwd函数,设定路径,之后的路径如果不设置就是默认在这个路径下,如果设置了其他的,可以是跟在这个路径之后。也可以是一个跟这个路径无关的新路径。
getwd()#"C:/Users/WangChengLong/Desktop/R/R总结"## [1] "D:/Rblog/rblog/content/R/R入门"# setwd("D:/code")#setwd("D:\\code")正斜杠或双反斜杠
# read.csv(file="data/GDP.csv")#D:/code/data/gdp.csv
# read.table("Rtest.txt")#D:/code/Rtest.txt
# read.csv(file="D:/R/data/shop.csv")读取纯文本文件
并不是单纯的纯文本,而是有一定格式的纯文本。并不是文章之类的文本。
| 函数 | 使用 | 实例 |
|---|---|---|
| read.table() | 以数据框的形式读取具有多列表格形式的文件数据 file∶文件路径 header∶逻辑值,用于指出文件的第一行是否为数据变量的名字。一般默认为header=F。如果第一行比其他行少一列,则默认第一列为行名,第一行为列名。 sep∶字符型,数据的分隔符。默认情况下,sep=““,此参数用于指定数据文件中每行中数据之间使用的分隔符。 quote∶指定包围字符型数据的字符。默认情况下,字符串可以被”或’括起,并且两种情况下,引号内部的字符都作为字符串的一部分。 dec∶字符型,制定小数点字符,默认为”.”一般不用修改. row.names∶保存行名的向量。未定义时以1、2、3、4.…代替. col.names∶指定列名的向量。缺省情况下是用”V”加上列序构成,即V1,V2,V3. nroWS∶整型数,用于指定从文件中读取的最大行数。 skip∶整型数,读取数据时从前面开始忽略的行数。 |
read.table(file=“D:/R/data/house.data.txt”,sep=““,nrows=5) read.table(file=”D:/R/data/house.data.txt”,sep=““,header=T,nrows=2) read.table(file=”D:/R/data/house.data.txt”,header=T,nrows=5,quote=“"’”) |
| read.csv() | 以数据框的格式读取逗号分隔的数据文件,默认header | |
| =TRUE。是read.table的变形 | read.csv(file, header = TRUE, sep =“,”,quote=“"”,dec =“.”,…) | |
| read.csv2() | 以数据框的格式读取分号分隔的数据文件,默认header | |
| =TRUE。是read.table的变形 | read.csv2(file, header = TRUE, sep =“,”,quote=“"”,dec =“.”,…) | |
| scan() | 在R语言中可以使用scan()函数从文本文件中读取数据或从键盘直接获取用户输入的数据。 scan(file =“, what = double(), sep =”“, quote, |
deC =“.”,skip= 0,nlines=0,…)
file∶用于指定要读取文件的路径和名字,如果为空或”“,则是要从键
盘中获取数据。
what∶用于给出要读取的数据的类型,支持的数据类型包括∶logical,,
integer, numeric, complex, character以及list。
sep∶用于指出文件中数据的分隔符,Scan默认数据是以空白进行分
隔。
quote∶制定包围字符型数据的字符。
dec∶字符型,制定小数点字符,默认为”“。
skip∶用于指定读取数据时,忽略文件前面的行数.
nlines∶指定要读取文件中数据的最大行数。
|
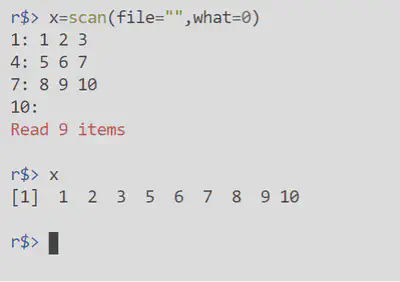
回车之后再回车代表输入的结束 read.fwf()|可以用来读取每一列数据宽度固定的数据
read. fwf(file, widths, header =FALSE, sep =” skip=0, row.names, col.names,…) |




写数据
写数据分为两种,一种是存入已有的文件中,一种是创建新的文件
| 函数 | 参数 | 实例 |
|---|---|---|
| write.table | 写纯文本数据,新文件 write.table(gnp,file=“…\lecture 2\GNP.txt”) |
|
| write.csv | 写excel数据,新文件 write.csv(gnp,file=“…\lecture 2\GNP.csv”) |
|
| write() | 既可以新文件,也可以写入,取决于append参数 X∶数据,通常是矩阵、向量等。 file∶是文件名 append∶默认为FALSE,append=TRUE指在原文件上填加数据 |
|
| sink | 之后输出的数据会被输出到该文件中。如果是一个新文件那么之后的输出都会显示在里面。不管append的T或F;但是如果是一个已有文件,那么如果不设置append=T,那么源文件中原本存在的都会被删除或者说替代。之后的所有输出还是出现在文件中 sink(file=““,append=FALSE,…) |
sink(file=“data/sink1.txt”,append=F) print(x) print(x) print(x) 第一次运行改程序,会创建一个新的sink1.txt文件,在里面输入三个x数据。但是在第二次运行时,里面不是6个,依然是三个,因为append是false,原来的被清除了。 |
| cat() | 既能输入到屏幕也能输入到文件中,取决于有无设置file属性 cat(…,file =““, sep =”“,append=F) |
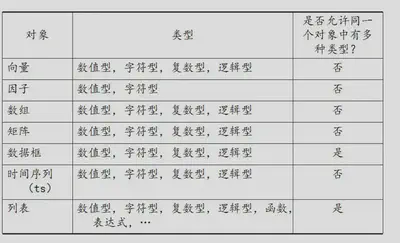
数据类型和类型转换
数据类型
- 数值型(numeric) 1e23,inf,-inf,NaN表示不是数字的
5/0,inf+inf为inf;inf-inf,0/0的结果为NaN。 - 逻辑型(complex) 包括FALSE,TRUE,和NA(缺失值)
- 复数型(logical)
- 字符型 (character)单或双引号包括

控制符和循环
分支语句
分支语句是用来判断的,条件满足则执行,条件不满足则不执行。
主要有下面五种
| 语句 | 使用 |
|---|---|
| if语句 | if()每个if语句只要条件满足就会执行 |
| if ……else…… |
if条件满足执行if下的语句,否则执行else下的语句 |
| ifelse | ifelse(?,x,y)满足条件为x,不满足为y,返回结果的长度和判断生成的逻辑值数目一致。有多少个逻辑值。就会返回多少个结果。 ifelse(?,c(),c()),满足时,取第一个向量的第i个,否则取第二个向量的第i个,向量中的元素可以循环取。 |
| if …… else if ……else if ……else |
只要有一个条件满足,其他条件就不会再执行。 |
| switch | switch(con,list)或 switch(con,case1,case2,case3,…) switch是多分支语句,一次只能比较一个变量,比较的可以是下标,如,1,2.如果下标范围在列表长度内,返回对应位置元素,否则什么都不返回。如果列表元素是有names的,则还可以通过names比较。 |
注意:
else或else if不可前面无其他内容,也就是不可以另起一行或者放在开头,一般是放在上一个if的内容后面
ifelse 与 if else的区别:
ifelse(con,expr1,expr2)中的条件判断中可以得到多个逻辑结果,有多少个逻辑结果,ifelse()的返回值就有多少个元素,且不同的逻辑结果取不同的值。
if(con) expr1 else expr2中的条件判断中只得到一个逻辑结果(如果 有多个逻辑结果,会自动取第一个,并抛出警告)。然后根据这个逻辑结果,取后面表达式的值。
if语句各判断条件的位置关系:
if语句可以有零个或一个else,但如果有else if语句,那么else语句必须在else if语句之后。
if语句可以有零或多个else if语句,else if语句必须放在else语句之前。
当有一个else if条件测试成功,其余的else.….if或else将不会被测试。