R数据对象
向量
创建向量
| 形式 | 用途 |
|---|---|
| n1:n2 | n1,n2大小不规定,生成从n1到n2的差为1或-1的等差序列 |
| seq(n1,n2,by=n3,length=n4) | 生成从n1到n2的步长为n3或者长度为n4的向量 |
| rep(n1,n2) | n1重复n2次的向量 |
| rep(c(),n2) | 向量c重复n2次 |
| rep(c(),each=n2) | 向量c中的每个元素重复n2次 |
| rep(c(),c()) | 前后两个长度必须相等,对应重复n次 |
| c() | 直接利用c函数生成无规律的向量 |
| scan() | 直接在键盘输入 |
| sequence(n1) | 生成从1到n1的向量 |
| sequence(c()) | c中每一个元素是一个n,依次生成从1到每一个n的向量,比如sequence(c(2,3))为12123 |
| numeric(n) | 生成一个长度为n的零向量 |
数值型向量以上方法都可用
字符型向量 可以用rep,c(),scan()
paste将字符串连接起来,并且设置连接的符号,默认是空格,也可以是空字符串或其他 符号
paste(c1,c2,c3,...sep="?")paste("a","b")#"a b" paste("a","b",sep="")#"ab" paste("a","b",sep=".")#"a.b" paste(c("a","b"),c(1,2))#"a 1" "b 2" paste(c("a","b"),1)#"a 1" "b 1"逻辑型向量 可以用rep, c(),scan()
也可以通过比较运算符得出逻辑运算符
复数型向量 可以用rep, c()


因子
因子是一组具有标签的序列。它用于存储分类类别。因子水平用于限制因子的取值范围。因子中的元素要么是因子水平中的值,要么是缺失值。
可以用factor函数和gl函数生成因子
| 函数 | 参数 | 实例 |
|---|---|---|
| factor(x,levels,lables, exclude,ordered,nmax) |
 |
factor(1:3,levels=1:3) [1] 1 2 3 Levels: 1 2 3 factor(1:3,levels=2:4) [1] Levels: 2 3 4 factor(1:3,levels=2:4,labels=c(“a”,“b”,“c”)) [1] Levels: a b c c中元素如果不属于levels,则显示为NA,labels可以改变水平名称。相应的c中元素的显示也会改变。 可以用levels函数查看因子水平或者更改因子水平 |
| gl(k,n,length,labels,ordered=FALSE) |
 length是总长度,n是水平总个数,默认1到n,k是每个水平重复数 |
gl(3,2,12) [1] 1 1 2 2 3 3 1 1 2 2 3 3 Levels: 1 2 3 |
时间序列

start=c(年份,第几个季度/第几个月)
start=c(月份,第几天)
ts(2:10,frequency=4,start=c(2020,2))
Qtr1 Qtr2 Qtr3 Qtr4
2020 2 3 4
2021 5 6 7 8
2022 9 10数组
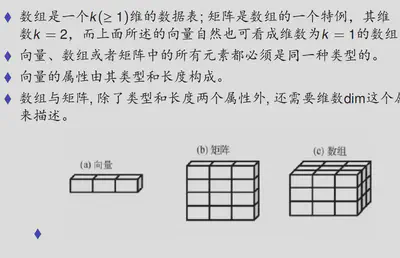
矩阵
创建矩阵
使用matrix函数创建矩阵 matrix(data,nrow,ncol,byrow=F,dimnames)
可以设置行数和列数,以及是否按行排,默认按行排;以及设置行列名(必须是列表)。
使用rbind(按行合并)和cbind(按列合并) 可以合并向量,数组,矩阵生成新的矩阵
rbind(x[,,1],x[,,2])
使用数组来生成
矩阵的运算
| 函数 | 用途 |
|---|---|
| t() | 矩阵转置,或者将一个向量变成矩阵 |
| diag() | 对矩阵使用提取对角元素,对向量使用生成对角阵,diag(diag(matrix(1:4,2,2)))可以提取一个矩阵的对角元素生成对角阵。 |
| dim() | 矩阵维度 |
| nrow() | 矩阵行数 |
| ncol() | 矩阵列数 |
| as.vector() | 矩阵拉直,转换成向量 |
| rbind() | 按行合并矩阵 |
| cbind() | 按列和并矩阵 |
| A*B | 矩阵的逐元乘积,对应位置元素相乘 |
| A%*%B | 矩阵的代数乘积 |
| det() | 方阵的行列式 |
| solve(A) | 矩阵的逆 |
| solve(A,b) | 求AX=b的解,b不给时,默认为单位矩阵,所以可以求逆 |
| eigen(A) | 求矩阵的特征值和特征向量 可以看到结果会有 |
| svd(A) | 对矩阵做奇异值分解 |
列表

列表可以在赋值时人为的给每个参数添加一个name,可以只添加一部分,可以不添加。
列表索引时有三种格式,且每次只能索引一个值
- 如果有name
- list$name
- list[[name]]
- 如果无name
- lsit[[n]](n为下标)
可以通过索引来进行列表的增删改,删除就是令该值为NULL。
子列表索引
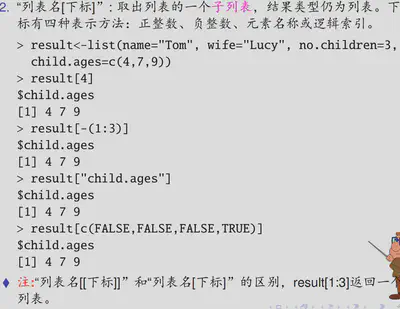
result=list(name="Tom",wife="Lucy",csex=c('m','m','f'),cages=c(4,7,9))
result[1]#会返回名字加值这个列表结构
result[[1]]#只会返回值列表的name属性可以通过names函数查看,无name的元素返回null。也可以通过names函数为list的元素命名。可以只命名前面的一部分。
数据框

创建数据框
| 方法 | 详情 |
|---|---|
| 利用data.frame函数 | 和列表类似,不过每一个元素的长度必须相同.每一个元素是一列。data.frame(name1=c(),name2=c(),name3=c()...),最好给每一个元素赋予一个名称。 |
| 利用向量 | 先创建相同长度的向量c1,c2,c3…,然后在用data.frame(c1,c2,c3,…)转化成数据框 |
| 利用列表 | 如果一个列表各元素长度相同,可以用as.data.frame()强制转化为数据框。 |
| 利用数组 | as.data.frame()转化,没有列名就为v1,v2,v3… |
| 利用矩阵 | as.data.frame(),列名和数组一样 |