抽样分布与参数估计和假设检验
抽样分布
常见抽样分布的总结
| 分布函数 | 数学形式 | 均值 | 方差 | 性质 | 图像 |
|---|---|---|---|---|---|
| 正态分布 |
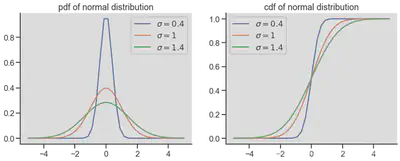 |
||||
| 卡方分布 | 设随机变量 |
n | 2n | (1)可加性 (2)当 (3)当自由度n>45时, |
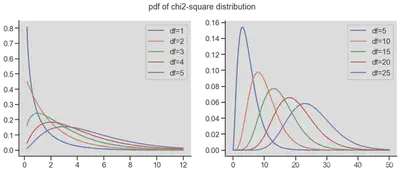 |
| t分布 | 设随机变量 |
当 |
当 |
(1)t(n)的方差比N(0,1)要大一些 (2)自由度为1的t分布称为柯西分布,期望不存在 (3)当 |
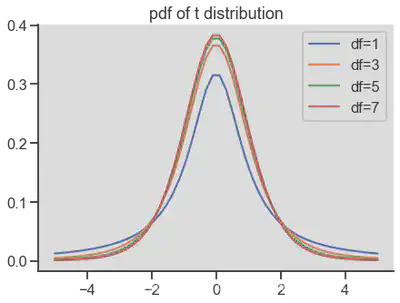 |
| F分布 | 设随机变量Y与Z相互独立,且Y和Z分别服从自由度为m和n的 |
(1) (2)如果随机变量X服从t(n)分布,则 |
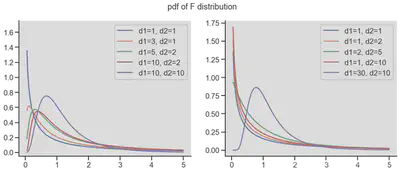 |
||
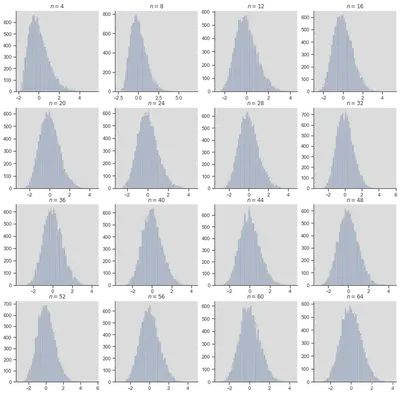
| 中心极限定理 | 不管总体的分布是什么,样本均值X的分布总是近似正态分布,只要总体的方差 |
0 | 1 | (1)通常认为 |
 |
参数估计
各种情况下的参数估计总结
参数估计的基本原理
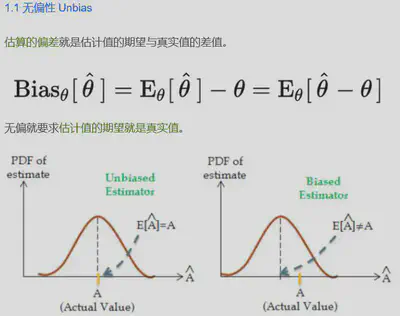
参数估计是为了估计一个总体的参数
通过构造统计量(估计量),从而利用样本来预测总体的参数,利用具体的样本算出来的统计量称为估计值。
点估计就是用估计值来估计总体参数
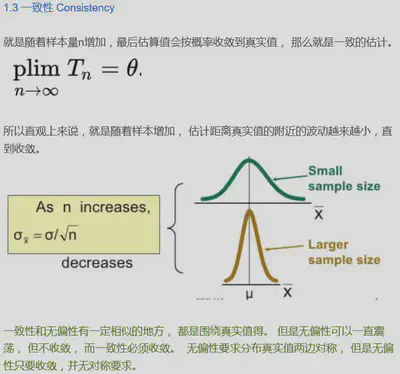
区间估计是构造服从一定分布的含未知参数的(但是注意这个参数被视作一个常数)统计量来估计总体参数的范围,当我们得知一个统计量的分布时,我们就可以得到它任一分位点的值,就可以得到该统计量一定范围区间的值(被称作置信水平),从而反推出此时参数的取值范围(被称作置信区间,最小值被称为置信下限,最大值被称为置信上限)。
置信水平
主观设定的值,取决于我们希望这个置信区间应该多宽,当样本量给定时,置信区间的宽度随着置信系数的增大而增大,置信区间越大,肯定越可靠。但是太宽的置信区间没有意义
这个水平是针对某个随机区间而言,我们永远不能说参数在某个具体区间内的概率为
置信区间
置信区间的解释是在n次抽样中,包含参数的区间的概率为
参数在一个区间的概率非1即0,在或者不在。
假设检验
假设检验的理解
参数估计是为了估计参数的范围,而假设检验是为了检验我们关于参数的假设值或者范围是否正确。这在实际生活中有很大的意义,我们希望来检测总体的参数有没有发生某些变化,假设检验给了我们科学的指导。
假设分为原假设,和备则假设。假设的检验有可能犯两类错误,一类是弃真(
弃真错误和取伪错误此消彼长,
假设检验的根本原则
假设检验依据的是小概率原则,也就是我们认为小概率的事件在一次试验中是几乎不可能发生的。如果发生了,就认为原假设有问题,我们就可以拒绝原假设。
假设检验也是通过构造服从一定分布含假设参数的统计量,通过分布我们可以选定小概率区间,如果估计值落在了小概率区间内,则拒绝原假设。
单边检验和双边检验中拒绝域的选择
**其实就是找确定为小概率区间的值**,对于双边检验来说,要检验的参数值确定,不需要考虑小概率区间的变化,而对于单边检验来说,我们要找确定为小概率区间的区间。我们先假定
以上看法不对单边检验就是找小概率区间来拒绝,但是双边检验是对问题的理解,比如关于
要理解,参数永远改变不了统计量的分布,统计量的分布是固定的,参数只是个常数,真正决定统计量分布的是样本。所以我们不管怎么假设参数实际上影响的使我们对于小概率区间的选择,而不是统计量的分布。统计量的小概率区间可以从两边或单边去选择。我们用样本去衡量
附录
样本均值和样本方差分布以及独立性的证明
定理:设随机样本
结论2易得,以下仅证明结论1和3。
证明:为证明结论1,首先给出三个引理如下:
引理1: 对任一
证明:注意到:
这里
引理2: 对任一$(X_i-,)服从二元正态分布.
证明:由引理1的证明可知:
引理3: 对于二元正态分布,协方差为0等价于独立。
证明:协方差为0等价于联合密度等于边际密度乘积等价于独立,得证。
由上述引理1—3,易知对任一
接下来考虑结论3。注意到
也就是
等式左边是n项独立标准正态分布的平方和,故服从
上述证明的核心是基于多元正态分布的典型性质,即不相关和独立等价,从而我们仅需证明变量不相关即可,使得独立性的证明变得简单易懂。